> For the complete documentation index, see [llms.txt](https://docs.tonic.ai/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.tonic.ai/app/generation/generators/generator-characteristics/differential-privacy.md).
# Differential privacy
Differential privacy is one technique that Tonic Structural uses to ensure the privacy of your data.
Differential privacy limits the effect of a single source record or user on the destination data. Someone who views the output of a process that has differential privacy cannot determine whether a particular individual's information was used to generate that output.
Data that is protected by a process with differential privacy cannot be reverse engineered, re-identified, or otherwise compromised.
## Generators that automatically have differential privacy
Any generator that does not use the underlying data at all is considered "[data-free](/app/generation/generators/generator-characteristics/data-free-generators.md)". A data-free generator always has differential privacy.
Several Structural generators are either always data-free, or are data-free if consistency is not enabled.
## Generators for which differential privacy is configurable
The configuration options for the [Categorical](/app/generation/generators/generator-reference/categorical.md) and [Continuous](/app/generation/generators/generator-reference/continuous.md) generators include a **Differential Privacy** toggle to enable or disable differential privacy.
### Categorical generator
The Categorical generator shuffles the values of a column, but preserves the overall frequency of the values. Note that NULL is considered its own category of value.
Differential privacy (disabled by default) further protects the privacy of your data. It:
1. First, adds noise to the frequencies of categories.
2. Next, if needed, removes rare categories from the possible samples.
These steps ensure that a single row of source data has limited influence on the output values. By default, the [privacy budget](/app/generation/generators/generator-characteristics/differential-privacy.md#privacy-budget) for this generator is $$\varepsilon = 1,$$with $$\delta = \frac{1}{10n}$$, where $$n$$is the number of rows.
Differential privacy is not appropriate when the data in each row is unique or nearly unique. As a general rule of thumb, categories that are represented by fewer than 15 rows are at risk of being suppressed.
Structural warns you when a column isn’t suitable for differential privacy. A column is not suitable for differential privacy if most or all categories have fewer than 15 rows.
### Continuous generator
The Continuous generator produces samples that preserve the individual column distributions and correlations between columns.
When differential privacy is enabled, noise is added to the individual distributions and the correlation matrix, using the mechanism described in \[[4](https://docs.tonic.ai/app/concepts/differential-privacy#references)].
The default privacy budget for this generator is $$\varepsilon = 1,$$with $$\delta = \frac{1}{10n}$$.
## More details: Mathematical formulation
Differential privacy is a property of a *randomized algorithm* $$\mathcal{M}$$*,* which takes as input a database $$D$$ and produces some output $$\mathcal{M}(D).$$The outputs could be counts or summary statistics or synthetic databases — the specific type is not important for this formulation.
For this formulation, we say two databases $$D$$and $$D'$$are neighbors if they differ by a single row.
For a given $$\varepsilon\geq 0$$, we say that $$\mathcal{M}$$is $$\varepsilon$$differentially private if, for all subset of outputs $$\mathcal{O}$$, we have:
$$
\operatorname{P}(\mathcal{M}(D)\in \mathcal{O}) \leq e^\varepsilon \operatorname{P}(\mathcal{M}(D')\in \mathcal{O})
$$
When $$\delta$$is non-zero, this is sometimes called *approximately differentially private*.
### Privacy budget
The parameter $$\varepsilon$$ is the privacy budget of the algorithm, and quantifies in a precise sense an upper bound on how much information an adversary can gain from observing the outputs of the algorithm on an unknown database.
Suppose an attacker suspects that our secret database$$D$$is one of two possible neighboring databases $$D\_1, D\_2$$, with some fixed odds.
If$$\mathcal{M}$$is $$\varepsilon$$differentially private, then observing $$\mathcal{M}(D)$$updates the the attacker's log odds of $$D=D\_1$$vs $$D=D\_2$$by at most $$\varepsilon$$.
The closer $$\varepsilon$$is to $$0$$, the better the privacy guarantee, as an attacker is more and more limited in what information they can learn from $$\mathcal{M}(D)$$.
Conversely, larger values of $$\varepsilon$$ mean that an attacker can *possibly* learn significant information by observing $$\mathcal{M}(D)$$.
### A simple example: counting
Suppose we want to count the number of users in a database that have some sensitive property. For example, the number of users with a particular medical diagnosis.
Dwork, McSherry, Nissim and Smith introduced in \[[2](https://docs.tonic.ai/app/concepts/differential-privacy#references)] the Laplace Mechanism as a way to publish these counts in a secure way, by adding noise sampled from the Laplace distribution.
This noise affords us plausible deniability. If the underlying count changed by $$\pm 1$$, then the probability of observing the same noisy output does not change by much:
$$
\operatorname{P}( \text{Noised} = k | \text{count} = n \pm 1) \leq \operatorname{exp}(1) \operatorname{P}(\text{Noised} = k | \text{count} = n)
$$
We illustrate this visually, showing the probability density function (pdf) of the observed values given true counts of $$n$$ (blue), $$n + 1$$ (orange), and $$n - 1$$ (green).
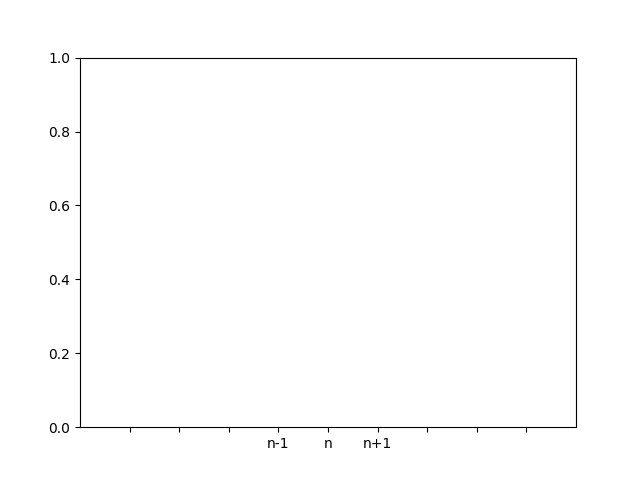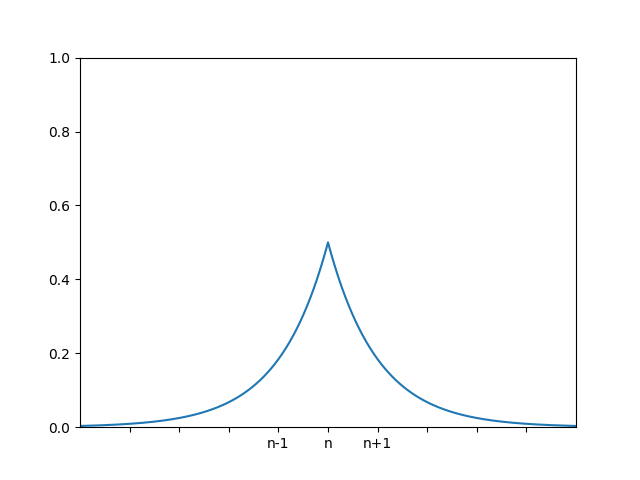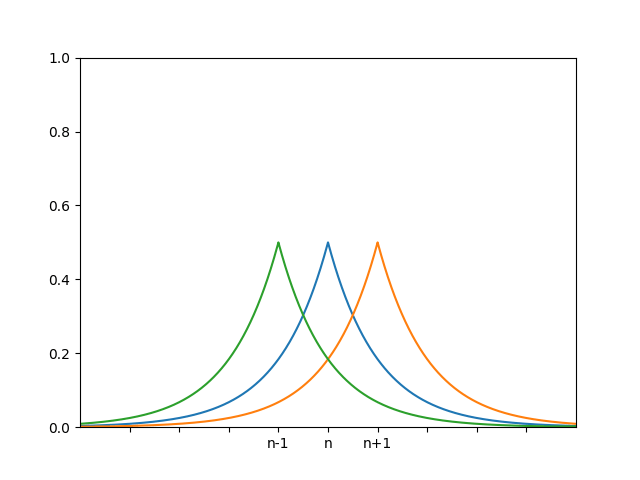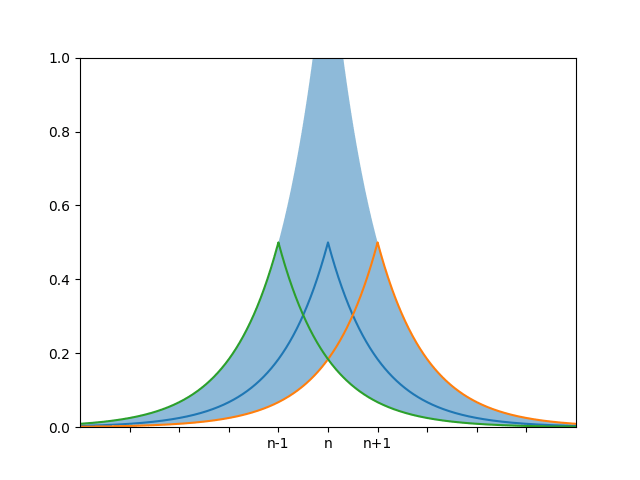
The blue shaded region shows that the the possibly noisy count values for $$n-1$$ and $$n+1$$ lie within a factor of $$\exp(1)$$ of the noisy count values of $$n$$, so this mechanism is differentially private with $$\varepsilon=1$$.
### Approximate differential privacy
A common relaxation, called *approximate differential privacy*, allows for flexible privacy analysis with noise drawn that is from a wider array of distributions than the Laplace distribution.
For example, the AnalyzeGauss mechanisms of \[[4](https://docs.tonic.ai/app/concepts/differential-privacy#references)], and differentially private gradient descent of \[[1](https://docs.tonic.ai/app/concepts/differential-privacy#references)], use Gaussian noise as a fundamental ingredient, which requires the following relaxation:
For a given $$\varepsilon\geq 0$$ and $$\delta\in\[0,1]$$, we say that $$\mathcal{M}$$is $$(\varepsilon,\delta)$$differentially private if, for all subset of outputs $$\mathcal{O}$$, we have:
$$
\operatorname{P}(\mathcal{M}(D)\in \mathcal{O}) \leq e^\varepsilon \operatorname{P}(\mathcal{M}(D')\in \mathcal{O}) +\delta
$$
The parameter $$\delta$$is often described as the risk of a (possibly catastrophic) privacy violation. While this formal definition does allow, for example, a mechanism that reveals a sensitive database with probability $$\delta$$, in practice this is not a plausible outcome with carefully designed mechanisms. Also, taking $$\delta$$to be small relative to the size of the database ensures that the risk of disclosure is low.
## References
1. Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS '16). Association for Computing Machinery, New York, NY, USA, 308–318. DOI:
2. Cynthia Dwork, Frank McSherry, Kobbi Nissim and Adam Smith. 2006 Calibrating Noise to Sensitivity in Private Data Analysis. In: Halevi S., Rabin T. (eds) Theory of Cryptography. (TCC '06). Lecture Notes in Computer Science, vol 3876. Springer, Berlin, Heidelberg. DOI:
3. Cynthia Dwork and Aaron Roth. 2014. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci. 9, 3–4 (August 2014), 211–407. DOI:
4. Cynthia Dwork, Kunal Talwar, Abhradeep Thakurta, and Li Zhang. 2014. Analyze gauss: optimal bounds for privacy-preserving principal component analysis. In Proceedings of the forty-sixth annual ACM symposium on Theory of computing (STOC '14). Association for Computing Machinery, New York, NY, USA, 11–20. DOI:
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://docs.tonic.ai/app/generation/generators/generator-characteristics/differential-privacy.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.